2026
|
 | Abdul Mannan Mohammed; Martin McCarthy; Carsten Neumann; Gerd Bruder; Dirk Reiners; Carolina Cruz-Neira The Personalization Paradox: Trade-offs Between Social Presence and Task Efficiency in Virtual Instructors Proceedings Article Forthcoming In: Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI '26), April 13--17, 2026, Barcelona, Spain, Forthcoming. @inproceedings{MohammedPersonalization2026,
title = {The Personalization Paradox: Trade-offs Between Social Presence and Task Efficiency in Virtual Instructors},
author = {Abdul Mannan Mohammed and Martin McCarthy and Carsten Neumann and Gerd Bruder and Dirk Reiners and Carolina Cruz-Neira},
url = {https://varlab.cs.ucf.edu/wp-content/uploads/2026/03/The-Personalization-Paradox-Trade-offs-Between-Social-Presence-and-Task-Efficiency-in-Virtual-Instructors.pdf},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
booktitle = {Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI '26), April 13--17, 2026, Barcelona, Spain},
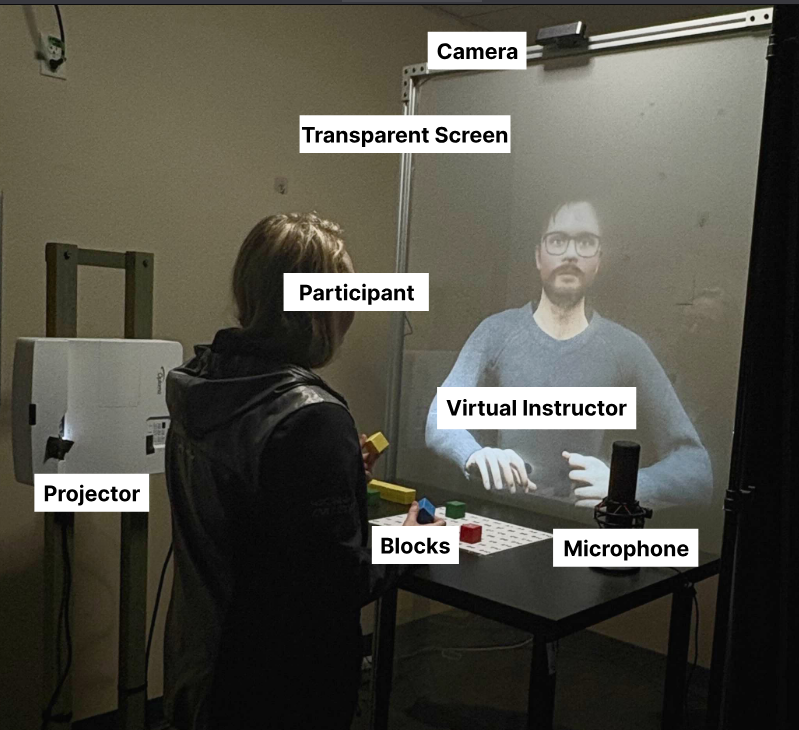
abstract = {Large language models continue to become utilized in training situations to power embodied virtual instructors in Mixed Reality (MR). As these models increase in sophistication, a key question emerges: does designing an agent with similarity to the instructee improve outcomes? We present a user study with four guided assembly conditions: a non-matched instructor employing real-life instructor's attributes, a personality-matched instructor, a gender- and voice-matched instructor, and a fully matched instructor reflecting the user's Big Five personality, cloned voice, and gender. Participants completed an ordered assembly task and reported on instructional quality. Results show that fully matched instructors were overwhelmingly preferred and significantly enhanced social presence and user experience. However, these subjective benefits did not translate into faster task completion, revealing a trade-off between engagement and efficiency. These findings offer critical guidance for designing future embodied virtual instructors and highlight the nuanced role of personalization in human–AI interaction.},
keywords = {},
pubstate = {forthcoming},
tppubtype = {inproceedings}
}
Large language models continue to become utilized in training situations to power embodied virtual instructors in Mixed Reality (MR). As these models increase in sophistication, a key question emerges: does designing an agent with similarity to the instructee improve outcomes? We present a user study with four guided assembly conditions: a non-matched instructor employing real-life instructor's attributes, a personality-matched instructor, a gender- and voice-matched instructor, and a fully matched instructor reflecting the user's Big Five personality, cloned voice, and gender. Participants completed an ordered assembly task and reported on instructional quality. Results show that fully matched instructors were overwhelmingly preferred and significantly enhanced social presence and user experience. However, these subjective benefits did not translate into faster task completion, revealing a trade-off between engagement and efficiency. These findings offer critical guidance for designing future embodied virtual instructors and highlight the nuanced role of personalization in human–AI interaction. |
| Abdul Mannan Mohammed; Martin McCarthy; Carsten Neumann; Gerd Bruder; Dirk Reiners; Carolina Cruz-Neira ARIA: Toward Human-Centered Embodied AI Instruction in Real-Time Augmented Reality Proceedings Article Forthcoming In: Proceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26), March 23–26, 2026, Paphos, Cyprus, Forthcoming. @inproceedings{MohammedARIA2026,
title = {ARIA: Toward Human-Centered Embodied AI Instruction in Real-Time Augmented Reality},
author = {Abdul Mannan Mohammed and Martin McCarthy and Carsten Neumann and Gerd Bruder and Dirk Reiners and Carolina Cruz-Neira},
url = {https://varlab.cs.ucf.edu/wp-content/uploads/2026/03/IUI2026_SystemsPaper__Final_Version_.pdf},
doi = {https://doi.org/10.1145/3742413.3789163},
year = {2026},
date = {2026-03-23},
urldate = {2026-03-23},
booktitle = {Proceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26), March 23–26, 2026, Paphos, Cyprus},
abstract = {Advances in artificial intelligence and embodied interaction in augmented reality (AR) are creating new opportunities for intelligent instructional systems that dynamically adapt to individual learners. However, sustaining real-time responsiveness while preserving natural, socially meaningful interaction remains a persistent challenge. This work introduces ARIA (Augmented Reality Instructional Agent), a real-time software architecture for embodied AI instruction in augmented reality. ARIA leverages large language models (LLMs) with adaptive prompt engineering to tailor dialogue style, instructional strategy, and persona expression to each user. Its modular pipeline is optimized for robust, low-latency performance, with benchmarks reported for responsiveness and system stability. To complement the technical evaluation, user experience was assessed through standardized questionnaires, offering insights into perceived personalization, trust, and interaction quality. Quantitative and qualitative results demonstrate that ARIA achieves sub-second responsiveness, high pragmatic and hedonic usability, and a strong sense of co-presence and instructional trust. This work contributes a unified framework and reference architecture for developing adaptive embodied agents that combine technical efficiency with human-centered design, highlighting how real-time responsiveness can serve as the foundation for relational engagement in embodied AI instruction.},
keywords = {},
pubstate = {forthcoming},
tppubtype = {inproceedings}
}
Advances in artificial intelligence and embodied interaction in augmented reality (AR) are creating new opportunities for intelligent instructional systems that dynamically adapt to individual learners. However, sustaining real-time responsiveness while preserving natural, socially meaningful interaction remains a persistent challenge. This work introduces ARIA (Augmented Reality Instructional Agent), a real-time software architecture for embodied AI instruction in augmented reality. ARIA leverages large language models (LLMs) with adaptive prompt engineering to tailor dialogue style, instructional strategy, and persona expression to each user. Its modular pipeline is optimized for robust, low-latency performance, with benchmarks reported for responsiveness and system stability. To complement the technical evaluation, user experience was assessed through standardized questionnaires, offering insights into perceived personalization, trust, and interaction quality. Quantitative and qualitative results demonstrate that ARIA achieves sub-second responsiveness, high pragmatic and hedonic usability, and a strong sense of co-presence and instructional trust. This work contributes a unified framework and reference architecture for developing adaptive embodied agents that combine technical efficiency with human-centered design, highlighting how real-time responsiveness can serve as the foundation for relational engagement in embodied AI instruction. |
| Abdul Mannan Mohammed; Martin McCarthy; Carsten Neumann; Gerd Bruder; Dirk Reiners; Carolina Cruz-Neira It's All in the Personality: A Comparative Study of Real, Ideal, and Customized Virtual Instructors for AR Assembly Tasks Proceedings Article Forthcoming In: Proceedings of the 2026 IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR); Daegu, South Korea, March 21-25, Forthcoming. @inproceedings{MohammedPersonality2026,
title = {It's All in the Personality: A Comparative Study of Real, Ideal, and Customized Virtual Instructors for AR Assembly Tasks},
author = {Abdul Mannan Mohammed and Martin McCarthy and Carsten Neumann and Gerd Bruder and Dirk Reiners and Carolina Cruz-Neira},
url = {https://varlab.cs.ucf.edu/wp-content/uploads/2026/03/Its-All-in-the-Personality-A-Comparative-Study-of-Real-Ideal-and-Customized-Virtual-Instructors-for-AR-Assembly-Tasks.pdf},
year = {2026},
date = {2026-03-21},
urldate = {2026-03-21},
booktitle = {Proceedings of the 2026 IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR); Daegu, South Korea, March 21-25},
abstract = {While embodied conversational agents driven by Large Language Models (LLMs) are emerging as valuable tools for instruction in Augmented Reality (AR), a key challenge lies in crafting their personalities to optimize both instructional efficacy and user engagement. To address this, we present findings from a within-subjects experiment that compared task performance and user experience with a LEGO assembly task. Participants received guidance from a real human instructor and three virtual counterparts, whose Big Five personality profiles were designed to be: (1) a direct replica of the real human, (2) an “ideal” profile based on pedagogical research, or (3) customized by the participant. Our results reveal a critical trade-off: instruction from the real expert resulted in superior task efficiency and clarity; however, among the virtual conditions, instructors with idealized or user-customized personalities fostered significantly higher levels of user engagement and social presence compared to the virtual replica. Crucially,
allowing users to customize their instructor’s persona led to the strongest preference for future interaction. These findings underscore that personality is a fundamental component in the design of AI-driven instructors, providing empirical evidence for navigating the balance between task-oriented guidance and personalized, socially resonant user experiences.},
keywords = {},
pubstate = {forthcoming},
tppubtype = {inproceedings}
}
While embodied conversational agents driven by Large Language Models (LLMs) are emerging as valuable tools for instruction in Augmented Reality (AR), a key challenge lies in crafting their personalities to optimize both instructional efficacy and user engagement. To address this, we present findings from a within-subjects experiment that compared task performance and user experience with a LEGO assembly task. Participants received guidance from a real human instructor and three virtual counterparts, whose Big Five personality profiles were designed to be: (1) a direct replica of the real human, (2) an “ideal” profile based on pedagogical research, or (3) customized by the participant. Our results reveal a critical trade-off: instruction from the real expert resulted in superior task efficiency and clarity; however, among the virtual conditions, instructors with idealized or user-customized personalities fostered significantly higher levels of user engagement and social presence compared to the virtual replica. Crucially,
allowing users to customize their instructor’s persona led to the strongest preference for future interaction. These findings underscore that personality is a fundamental component in the design of AI-driven instructors, providing empirical evidence for navigating the balance between task-oriented guidance and personalized, socially resonant user experiences. |
2025
|
| Taylor Laird, Jasmine Joyce DeGuzman, Gerd Bruder, Carolina Cruz-Neira, Dirk Reiners You Have Arrived... Kind of: Investigating the Limits of Undetectable Destination Displacement During Teleportation Proceedings Article In: Proceedings of the 2025 31st ACM Symposium on Virtual Reality Software and Technology, pp. 1–11, 2025. @inproceedings{lairddeguzman2025you,
title = {You Have Arrived... Kind of: Investigating the Limits of Undetectable Destination Displacement During Teleportation},
author = {Taylor Laird, Jasmine Joyce DeGuzman, Gerd Bruder, Carolina Cruz-Neira, Dirk Reiners},
url = {https://varlab.cs.ucf.edu/wp-content/uploads/2026/03/You_Have_Arrived____Kind_of__Investigating_the_Limits_of_Undetectable_Destination_Displacement_During_Teleportation.pdf},
doi = {https://doi.org/10.1145/3756884.3766040},
year = {2025},
date = {2025-11-12},
booktitle = {Proceedings of the 2025 31st ACM Symposium on Virtual Reality Software and Technology},
journal = {Proceedings of the 2025 31st ACM Symposium on Virtual Reality Software and Technology},
pages = {1--11},
abstract = {Teleportation has become a popular locomotion method for virtual reality due to lesser demands on physical space and decreased levels of motion sickness compared to other methods. However, prior work has shown that these advantages come at the cost of impaired spatial perception and awareness, the extent to which is still largely unknown. In this work, we present a within-subjects study (N = 29) that explores the effects of teleportation on spatial perception by investigating how much humans can be unknowingly displaced relative to their intended destination during teleportation. After teleporting to the specified location, participants indicated the direction and magnitude (small, medium, large) of the perceived shift or rotation. Displacement from the target happened either as a translation in the forward- or strafe-axis, or a rotation about the up-axis at the intended target. Each displacement condition included eleven offsets that were repeated six times. Our results indicate points of subjective equality, which show a significant perceptual shift along the forward-direction, as well as detection thresholds, which indicate a comparatively wide range in which humans are unable to detect induced shifts. Furthermore, our results show that even if humans are able to detect these shifts, larger ones can be introduced before their magnitudes are rated as medium or large, which provides ample opportunities for interface designers who want to leverage these results in virtual reality.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Teleportation has become a popular locomotion method for virtual reality due to lesser demands on physical space and decreased levels of motion sickness compared to other methods. However, prior work has shown that these advantages come at the cost of impaired spatial perception and awareness, the extent to which is still largely unknown. In this work, we present a within-subjects study (N = 29) that explores the effects of teleportation on spatial perception by investigating how much humans can be unknowingly displaced relative to their intended destination during teleportation. After teleporting to the specified location, participants indicated the direction and magnitude (small, medium, large) of the perceived shift or rotation. Displacement from the target happened either as a translation in the forward- or strafe-axis, or a rotation about the up-axis at the intended target. Each displacement condition included eleven offsets that were repeated six times. Our results indicate points of subjective equality, which show a significant perceptual shift along the forward-direction, as well as detection thresholds, which indicate a comparatively wide range in which humans are unable to detect induced shifts. Furthermore, our results show that even if humans are able to detect these shifts, larger ones can be introduced before their magnitudes are rated as medium or large, which provides ample opportunities for interface designers who want to leverage these results in virtual reality. |
2024
|
| Abdul Mannan Mohammed; Azhar Ali Mohammad; Jason A. Ortiz; Carsten Neumann; Grace Bochenek; Dirk Reiners; Carolina Cruz-Neira
A Human Digital Twin Architecture for Knowledge-Based Interactions and Context-Aware Conversations Conference 2024 Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC), 2024. @conference{mohammed2024HDT,
title = {A Human Digital Twin Architecture for Knowledge-Based Interactions and Context-Aware Conversations},
author = {Abdul Mannan Mohammed and Azhar Ali Mohammad and Jason A. Ortiz and Carsten Neumann and Grace Bochenek and Dirk Reiners and Carolina Cruz-Neira
},
doi = {https://doi.org/10.48550/arXiv.2504.03147},
year = {2024},
date = {2024-12-04},
pages = {10},
publisher = {2024 Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC)},
abstract = {Recent developments in Artificial Intelligence (AI) and Machine Learning (ML) are creating new opportunities for Human-Autonomy Teaming (HAT) in tasks, missions, and continuous coordinated activities. A major challenge is enabling humans to maintain awareness and control over autonomous assets, while also building trust and supporting shared contextual understanding. To address this, we present a real-time Human Digital Twin (HDT) architecture that integrates Large Language Models (LLMs) for knowledge reporting, answering, and recommendation, embodied in a visual interface.
The system applies a metacognitive approach to enable personalized, context-aware responses aligned with the human teammate's expectations. The HDT acts as a visually and behaviorally realistic team member, integrated throughout the mission lifecycle, from training to deployment to after-action review. Our architecture includes speech recognition, context processing, AI-driven dialogue, emotion modeling, lip-syncing, and multimodal feedback. We describe the system design, performance metrics, and future development directions for more adaptive and realistic HAT systems. },
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Recent developments in Artificial Intelligence (AI) and Machine Learning (ML) are creating new opportunities for Human-Autonomy Teaming (HAT) in tasks, missions, and continuous coordinated activities. A major challenge is enabling humans to maintain awareness and control over autonomous assets, while also building trust and supporting shared contextual understanding. To address this, we present a real-time Human Digital Twin (HDT) architecture that integrates Large Language Models (LLMs) for knowledge reporting, answering, and recommendation, embodied in a visual interface.
The system applies a metacognitive approach to enable personalized, context-aware responses aligned with the human teammate's expectations. The HDT acts as a visually and behaviorally realistic team member, integrated throughout the mission lifecycle, from training to deployment to after-action review. Our architecture includes speech recognition, context processing, AI-driven dialogue, emotion modeling, lip-syncing, and multimodal feedback. We describe the system design, performance metrics, and future development directions for more adaptive and realistic HAT systems. |
2023
|
| Jason A Ortiz; Carolina Cruz-Neira
Workspace VR: A Social and Collaborative Telework Virtual Reality Application Conference Companion Publication of the 2023 Conference on Computer Supported Cooperative Work and Social Computing, CSCW '23 Companion Association for Computing Machinery, Minneapolis, MN, USA, 2023, ISBN: 9798400701290. @conference{ortiz2023workspace,
title = {Workspace VR: A Social and Collaborative Telework Virtual Reality Application},
author = {Jason A Ortiz and Carolina Cruz-Neira
},
url = {https://varlab.cs.ucf.edu/wp-content/uploads/2025/05/3584931.3607502-5.pdf},
doi = {10.1145/3584931.3607502},
isbn = {9798400701290},
year = {2023},
date = {2023-10-14},
urldate = {2023-10-14},
booktitle = {Companion Publication of the 2023 Conference on Computer Supported Cooperative Work and Social Computing},
pages = {381–383},
publisher = {Association for Computing Machinery},
address = {Minneapolis, MN, USA},
series = {CSCW '23 Companion},
abstract = {COVID-19 lockdowns accelerated user adoption of remote collaboration technologies such as Zoom and Microsoft Teams. Despite the challenges of working remotely, many knowledge workers still desire the flexibility of hybrid work and its personal benefits allowing for more productive individual work. However, return-to-office (RTO) mandates suggest an inclination that in-office work allows for more productive teamwork. To resolve these conflicting desires, Workspace VR was created. Unlike other social telework virtual reality (VR) applications, Workspace VR enables uncoordinated, social, collaborative, and productive individual work and teamwork via virtual avatars, workspaces, and integration with user computers. Designed for Meta Quest devices, users can feel like they are working together with others without constraints in Workspace VR.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
COVID-19 lockdowns accelerated user adoption of remote collaboration technologies such as Zoom and Microsoft Teams. Despite the challenges of working remotely, many knowledge workers still desire the flexibility of hybrid work and its personal benefits allowing for more productive individual work. However, return-to-office (RTO) mandates suggest an inclination that in-office work allows for more productive teamwork. To resolve these conflicting desires, Workspace VR was created. Unlike other social telework virtual reality (VR) applications, Workspace VR enables uncoordinated, social, collaborative, and productive individual work and teamwork via virtual avatars, workspaces, and integration with user computers. Designed for Meta Quest devices, users can feel like they are working together with others without constraints in Workspace VR. |